Как обработать 10 000 задач за $5 вместо месяца работы сотрудников

В большинстве компаний до сих пор есть большой пласт задач, который выполняется вручную. Это не потому, что их нельзя автоматизировать, а потому что классические методы автоматизации (скрипты, парсеры, регекспы) там не работают.
Речь про задачи, где нужно понять смысл текста, а не просто извлечь данные.
Типичные примеры:
- кратко описать документ
- выделить суть задачи
- классифицировать контент
- нормализовать разрозненные данные
- привести всё к единому формату
Раньше такие задачи почти всегда отдавались людям. Сегодня — уже нет.
Проблема: объём убивает производительность
Есть важный момент, который часто недооценивают:
Скорость человека почти не масштабируется с ростом объёма
Если сотрудник тратит 1–2 минуты на задачу, то:
- 100 задач → ~2–3 часа
- 1 000 задач → ~2–3 дня
- 10 000 задач → ~1 месяц работы
При этом:
- устаёт
- падает качество
- растёт количество ошибок
Почему не работает “обычная автоматизация”
Можно задать логичный вопрос: почему бы просто не написать парсер?
Проблема в том, что данные выглядят примерно так:
- неструктурированный текст
- куски markdown
- вставки изображений
- разный формат задач
- непредсказуемые формулировки
Например, одна задача может содержать:
- условие
- картинку (с описанием)
- темы
- служебные поля
И всё это — в разном виде.
Классический код здесь ломается, потому что:
- нет фиксированной структуры
- нет стабильных паттернов
- смысл задачи важнее формы
Кейc: обработка 10 000 учебных задач
Задача:
Взять большой массив задач (ОГЭ/ЕГЭ) из открытых источников и для каждой:
- сформировать краткое название
- сделать сжатое описание (1–2 предложения)
- указать, какие навыки проверяются
Пример входных данных:
{
"id": "cmob72y4900xa8hsmkuzqz9hk",
"createdAt": "2026-04-23T08:03:28.953Z",
"updatedAt": "2026-04-23T08:03:28.953Z",
"createdById": "cmo9nz7nz00008hs7uhy2mp6x",
"kBConceptId": "cmob72y4900x88hsmbirs7ii0",
"name": "Впишите правильный ответ.",
"description": "",
"content": "Впишите правильный ответ.\n\n\n\nУгол A трапеции ABCD с основаниями AD и BC , вписанной в окружность, равен 35° . Найдите угол B этой трапеции. Ответ дайте в градусах.\n\n \n\n \n\n \n\ni\n\nСВОЙСТВА ЗАДАНИЯ\n\nКЭС:\n\n7.3 Многоугольники\n\n7.4 Окружность и круг\n\n7.5 Измерение геометрических величин\n\nТип ответа:\n\nКраткий ответ\n\nНомер: 54330A",
"variants": [],
"Files": [
{
"id": "cmo9p2qbm00xfp20p79ocn3is",
"path": "external/fp/oge/DE0E276E497AB3784C3FC4CC20248DC0/54330A_0_xs3qstsrc289E0EB201B5B3814F95C32B0765D5BA_1_1485519697.png",
"name": "Вписанный четырехугольник",
"description": "Геометрическая схема, изображающая четырехугольник, вписанный в окружность.",
"content": "На изображении показан круг. Внутри круга расположен четырехугольник с вершинами A, B, C и D. Все четыре вершины фигуры лежат на окружности, что делает его вписанным четырехугольником. Стороны четырехугольника являются хордами окружности. По внешнему виду фигура напоминает равнобедренную трапецию, так как верхняя сторона BC кажется параллельной нижней стороне AD.",
"filename": "54330A_0_xs3qstsrc289E0EB201B5B3814F95C32B0765D5BA_1_1485519697.png",
"mimetype": "image/png",
"encoding": "binary",
"hash": null,
"size": "693",
"rank": null,
"Gallery": null,
"createdAt": "2026-04-22T06:51:39.586Z",
"updatedAt": "2026-04-22T10:47:35.501Z",
"CreatedBy": "cmo9nz7nz00008hs7uhy2mp6x"
}
],
"Topics": [
{
"id": "cmob1fmc200398hwcs0vawohj",
"createdAt": "2026-04-23T05:25:22.515Z",
"updatedAt": "2026-04-23T05:25:22.515Z",
"type": "Index:SubTopic",
"name": "Многоугольники",
"description": null,
"content": null,
"code": "oge-Mathematics-7.3",
"data": { "grades": [8, 9], "isInPreviousYears": true },
"createdById": "cmo9nz7nz00008hs7uhy2mp6x",
"parentId": "cmob1fmbb002x8hwcvt4j3nyn",
"rootId": "cmob1fm7a00018hwco95gut21"
},
{
"id": "cmob1fmcb003d8hwcqgc4k3p2",
"createdAt": "2026-04-23T05:25:22.523Z",
"updatedAt": "2026-04-23T05:25:22.523Z",
"type": "Index:SubTopic",
"name": "Окружность и круг",
"description": null,
"content": null,
"code": "oge-Mathematics-7.4",
"data": { "grades": [6, 7, 8, 9], "isInPreviousYears": true },
"createdById": "cmo9nz7nz00008hs7uhy2mp6x",
"parentId": "cmob1fmbb002x8hwcvt4j3nyn",
"rootId": "cmob1fm7a00018hwco95gut21"
},
{
"id": "cmob1fmck003h8hwcp19xglzf",
"createdAt": "2026-04-23T05:25:22.532Z",
"updatedAt": "2026-04-23T05:25:22.532Z",
"type": "Index:SubTopic",
"name": "Измерение геометрических величин",
"description": null,
"content": null,
"code": "oge-Mathematics-7.5",
"data": { "grades": [7, 8, 9], "isInPreviousYears": true },
"createdById": "cmo9nz7nz00008hs7uhy2mp6x",
"parentId": "cmob1fmbb002x8hwcvt4j3nyn",
"rootId": "cmob1fm7a00018hwco95gut21"
}
]
}
Пример запроса, включая системное сообщение:
const messages: LLMClientChatMessage[] = [
{
role: LLMChatMessageRole.system,
content: `## Тебе будет дана структурированная информация задач из школьной программы ОГЭ/ЕГЭ.
Твоя задача проанализировать весь предоставленный контент и составить name и description задачи, на русском языке.
- name - просто строка
- description - текст в формате markdown, буквально 1-3 предложения, с главной выжимкой о чем эта задача. Так же надо коротко указать какие навыки затрагивает задача.
По формату
### Примерная структура Excepcise:
{
"id": "cmocc9ddq024wp80p5cuj7otc",
"createdAt": "2026-04-24T03:16:12.926Z",
"updatedAt": "2026-04-24T03:16:12.926Z",
"createdById": "cmo9nz7nz00008hs7uhy2mp6x",
"kBConceptId": "cmocc9ddp024up80pbs605na6",
"name": ".......",
"description": "",
"content": "Описание задачи......",
"variants": [],
"Files": [],
"Topics": [
{
"id": "cmobafe68000l8hxov8dbdx9a",
"createdAt": "2026-04-23T09:37:08.480Z",
"updatedAt": "2026-04-23T09:37:08.480Z",
"type": "Index:SubTopic",
"name": "Дискретность данных",
"description": null,
"content": ".....",
"code": "oge-Informatics-2.1",
"data": {
"grades": [
7
],
"isInPreviousYears": true
},
}
]
}
## На что следует обратить внимание?
1. Excepcise::content
Тут почти полное описание задачи будет.
2. variants - варианты ответа. Часто это будет ссылки на файлы
3. Files
Тут будет детальная информация о прилагаемых файлах, если они есть. В их описаниях указано что содержится на этих картинках, если это картинки.
## Формат ответа: JSON без дополнительного текста. Только сам JSON-объект.
{
"name": "Краткое название задачи",
"description": "Краткое описание (1-2 предложения)"
}
`,
},
{
role: LLMChatMessageRole.user,
content: [
{
type: 'text',
text: `Проанализируй эту задачу и верни ответ СТРОГО в формате JSON без дополнительного текста:
{
"name": "краткое название изображения",
"description": "краткое описание (1-3 предложения)"
}`,
},
{
type: 'text',
// Тут полный объект задачи, описанная выше
text: JSON.stringify(complexExcercise, null, 2),
},
],
},
]
Пример результата:
{
"name": "Вписанный четырехугольник в окружности",
"description": "Геометрическая задача на нахождение углов в вписанном четырехугольнике. Проверяет знание свойств окружности и углов."
}
Важно:
- входные данные — хаотичные
- формат не унифицирован
- требуется понимание смысла
Решение: LLM вместо парсера
Для обработки использовалась языковая модель (LLM).
Подход:
- На вход подаётся вся структура задачи (JSON)
- Модель анализирует содержание
- Возвращает строго заданный JSON:
{
"name": "...",
"description": "..."
}
Дальше:
- идёт валидация
- ошибки автоматически перерабатываются
- небольшой хвост отдаётся человеку
Экономика: цифры, которые меняют подход
Человек
- ~1.5 минуты на задачу
- 10 000 задач → ~250 часов
- ≈ 1–1.5 месяца работы
LLM (облачная модель)
- ~2000 токенов вход
- ~1000 токенов выход
Стоимость:
- ≈ $0.0004–0.0005 за задачу
Итого:
- 10 000 задач → ~$5–10
Локальная модель (реальный кейс)
Использовалась: haih-agent + llama.cpp + Qwen3.5-4B-BF16.gguf (Все входит в состав https://github.com/haih-net/agent )
Видеокарта: RTX5080 16Gb. Но тут можно и сильно меньше, так как с этой картой ллм загружается с контекстом 100 000 токенов, а по факту и 5-10 тысяч токенов достаточно. Тем не менее, сильно старую карту тоже нельзя, потому что тогда скорость генерации сильно упадет, то есть, думаю, меньше RTX4060 8Gb не стоит, лучше уж тогда по апи google gemeni 3.5 flash light использовать.
Результат:
- практически нулевая стоимость
- стабильное качество
- полный контроль над процессом
Производительность (реальные логи)
{
"cache_n": 0,
"prompt_n": 2043,
"prompt_ms": 725.825,
"prompt_per_token_ms": 0.35527410670582477,
"prompt_per_second": 2814.7280680604827,
"predicted_n": 1812,
"predicted_ms": 24131.802,
"predicted_per_token_ms": 13.317771523178807,
"predicted_per_second": 75.08763746694093
}
Фрагмент обработки одной задачи:
- вход: ~2000 токенов
- выход: ~1800 токенов
- скорость генерации: ~75 токенов/сек
- время: ~24 секунды
Это означает:
- ~2–3 задачи в минуту на одной машине
- ~150–200 задач в час
- масштабируется линейно (параллелизм)
Качество: что с ошибками
Важно понимать:
LLM не даёт 100% идеального результата.
Типичная картина:
- 97–99% задач — корректны
- 1–3% — проблемы (формат, пустые поля и т.п.)
Решение:
- автоматическая валидация
- повторная обработка
- оставшиеся ~1% → человеку
Итог:
- вместо 10 000 задач вручную
- человек обрабатывает ~100 задач
Почему это работает
Ключевое отличие от старых подходов:
Модель понимает смысл, а не структуру
Она может:
- интерпретировать текст
- учитывать контекст
- игнорировать мусор
- делать обобщения
То, что раньше требовало человека — теперь автоматизируется.
Где это применимо в бизнесе
Этот кейс — не про образование. Это универсальный паттерн.
Подходит для:
Контент
- генерация описаний товаров
- нормализация карточек
- обработка отзывов
Документы
- краткие выжимки
- классификация
- извлечение смысловых блоков
Поддержка
- разбор тикетов
- категоризация обращений
Данные
- очистка “грязных” массивов
- приведение к единому виду
Ключевой вывод
Раньше автоматизация выглядела так:
Если нельзя описать алгоритм — нужен человек
Теперь:
Если человек может сделать — почти всегда можно автоматизировать через LLM
Итог
В этом кейсе:
- 10 000 задач
- хаотичные входные данные
- требуется понимание смысла
Результат:
- $5–10 через облако
- ≈ $0 локально
- вместо месяца работы — несколько часов машинного времени
Что это меняет
Самое важное:
Стоимость обработки теперь зависит не от сложности, а почти только от объёма — и остаётся крайне низкой
Это открывает новые возможности:
- обрабатывать то, что раньше “слишком дорого”
- масштабировать без роста команды
- автоматизировать смысловую работу, а не только техническую
Если коротко: мы перешли от мира, где человек — узкое место, к миру, где объём перестал быть проблемой.
UPD: За 1.59 часа обработалось 400 задач. Количество обшибок примерно 0.5%
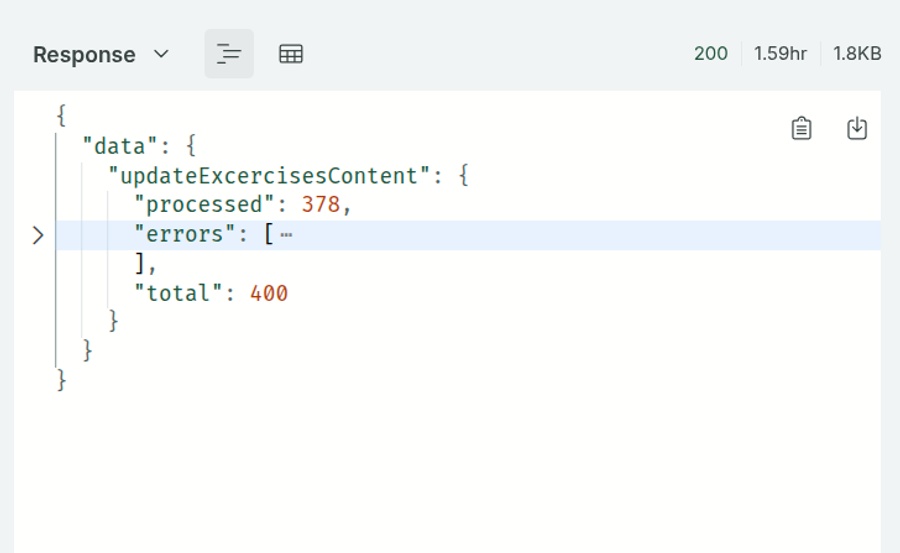
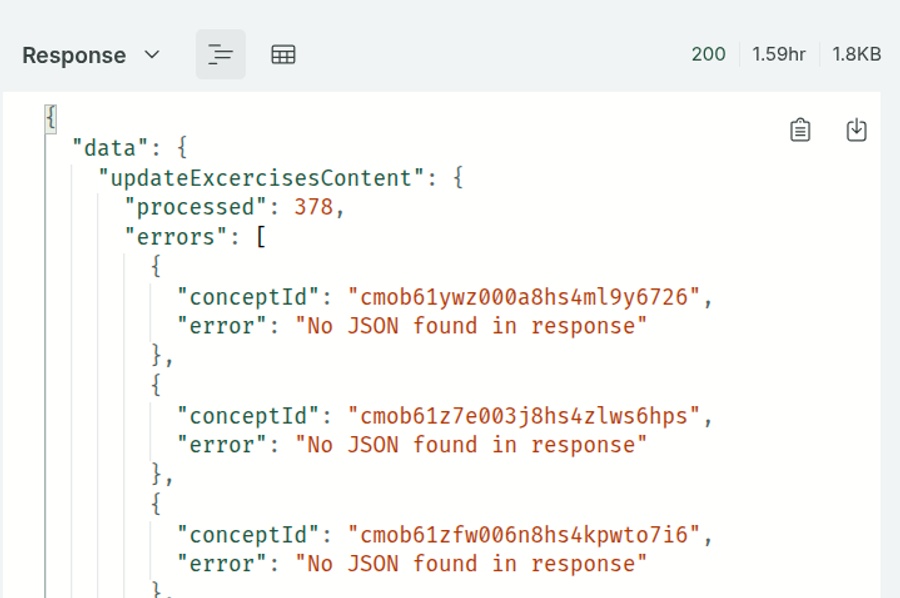
Обработка ошибок тут специально прописана и довольно жесткая: проверяется не только, чтобы ответ был в формате JSON, но и оба поля заполнены.
const response = await llmClient.chatCompletion({
messages,
max_tokens: 5000,
temperature: 0.3,
})
const responseText = response.choices[0]?.message?.content
if (typeof responseText !== 'string') {
throw new Error('Empty response from LLM')
}
const jsonMatch = responseText.match(/\{[\s\S]*\}/)
if (!jsonMatch) {
throw new Error('No JSON found in response')
}
const result: ImageRecognitionResult = JSON.parse(jsonMatch[0])
if (!result.name) {
throw new Error('Не заполнено название')
}
if (!result.description) {
throw new Error('Не заполнено описание')
}
await prisma.kBConcept.update({
where: { id: complexExcercise.kBConceptId.toString() },
data: {
name: result.name,
description: result.description,
},
})
}
Как правило, если все заполнено, то ответ корректный. А необработанные задачи можно будет просто потом еще раз прогнать.